Welcome to the Developer Update for October 23, 2025.

Today’s featured world is the VRChat Home world by us!!!
Announcements
The Spookality Row is Up!
Spookality is our annual celebration of the dark, spooky, and ██████. This year, creators had a chance to submit avatars and worlds between September 22 and October 13. They did – a lot!
Yesterday, we announced the winners!
The avatar winners:
ARCON Experiment Tera by cubee_cb
AVTR_FORGOTTEN_FINAL․FBX by Katten?
Edgar by YemmieGoat
Zap by MayoCube
Signal Beast by DekaWolf
Happy Garry by Chá Math
VCR Repairman by Octuplex
PlayBack by Murdoll
Dr Whaddastein’s Maculate Investigator by Whaddageek
Lynarie by SilverCherry
…and the world winners:
Specter Spectare by Crazium
The 3rd Answer by Maki Maki
Dark Caves by Puppet~
[REDACTED] by Salena
Chiaroscuro by Katchy
Chrono Hollow by へむへむ
Madness Manor by Keako
Project T․U․B․E․S by Mr Mycelium
Outrun by Jordo
Phantom Boat by NoobPete
You can see the full winners announcement post here! Go check 'em all out – and don’t forget, the world/avatar rows contain a lot more than just the winners!
A Reminder to Upgrade to the Latest SDK!
Last week we reminded you about upgrading to the latest version of the SDK. We’re doing it again!
In about a week, we will start blocking new avatars from being uploaded by older SDKs. That means you need to update to our latest version, SDK 3.9.0!
You’ll be able to edit old avatars without issue – but if you try to upload a new one, it will be blocked. So get to updating!
2025.3.4 Released!
2025.3.4 brings with it a brand-new tab in VRChat: the Shop!
What can you find in the Shop? Stuff! What kind of stuff? Well, you’ll see!
In short: you’ll be able to buy all kinds of things in the Shop: that might mean Items, it might mean Emoji, it might mean Stickers, it also might mean crazier things like, say… Portals.
…it also brought CANDY QUEST!
Begin Your CANDY QUEST
Grab your FREE Candy Codex from the Shop! Alongside the Candy Codex, you’ll notice a bunch of new listings for Spookality! Two that might immediately jump out at you are Treats and Kath.
Treats and Kath are both Companions. Companions follow you around and can be interacted with in some way. In the case of Treats and Kath, they’ll give out candy to others… if they’re patient.
When you see a Treats or Kath in the wild, pull out your Candy Codex! Either Companion might signal that they want to give you a treat. When they do, give 'em a head pat, and you’ll be rewarded with a piece of candy. As a note, you can’t get candy from your own Companion – you’ve gotta get them from others!
Fill out your Candy Codex to unlock a special badge!
Or, to put it another way, you’ve gotta get out there and do a little trick-or-treating. Go visit your friends! Go check out a new world! Go find something spooky to attend via the Event Calendar!
You can read more here!
2025.4.1 is in Open Beta!
This release, currently in beta, brings a lot: Boops, the Live Now tab, signing into VRChat via Discord, Warp Effects, a new reporting flow, instance linking, and so much more.
Go read all of it here!
Sign into VRChat… with Discord!
We’ve released Login with Discord on Web for all users! When visiting the VRChat website, you can click Log in with Discord on the login page.

If you’ve never logged in with Discord before, VRChat will automatically look up your existing VRChat account using your Discord account’s verified email.

After performing the required security checks, you will have successfully linked your Discord account to your VRChat account!
If you’re logging in with Discord for the first time, and your verified Discord account’s email does not link to an existing VRChat account, you will be prompted to create a new Discord Linked VRChat account.
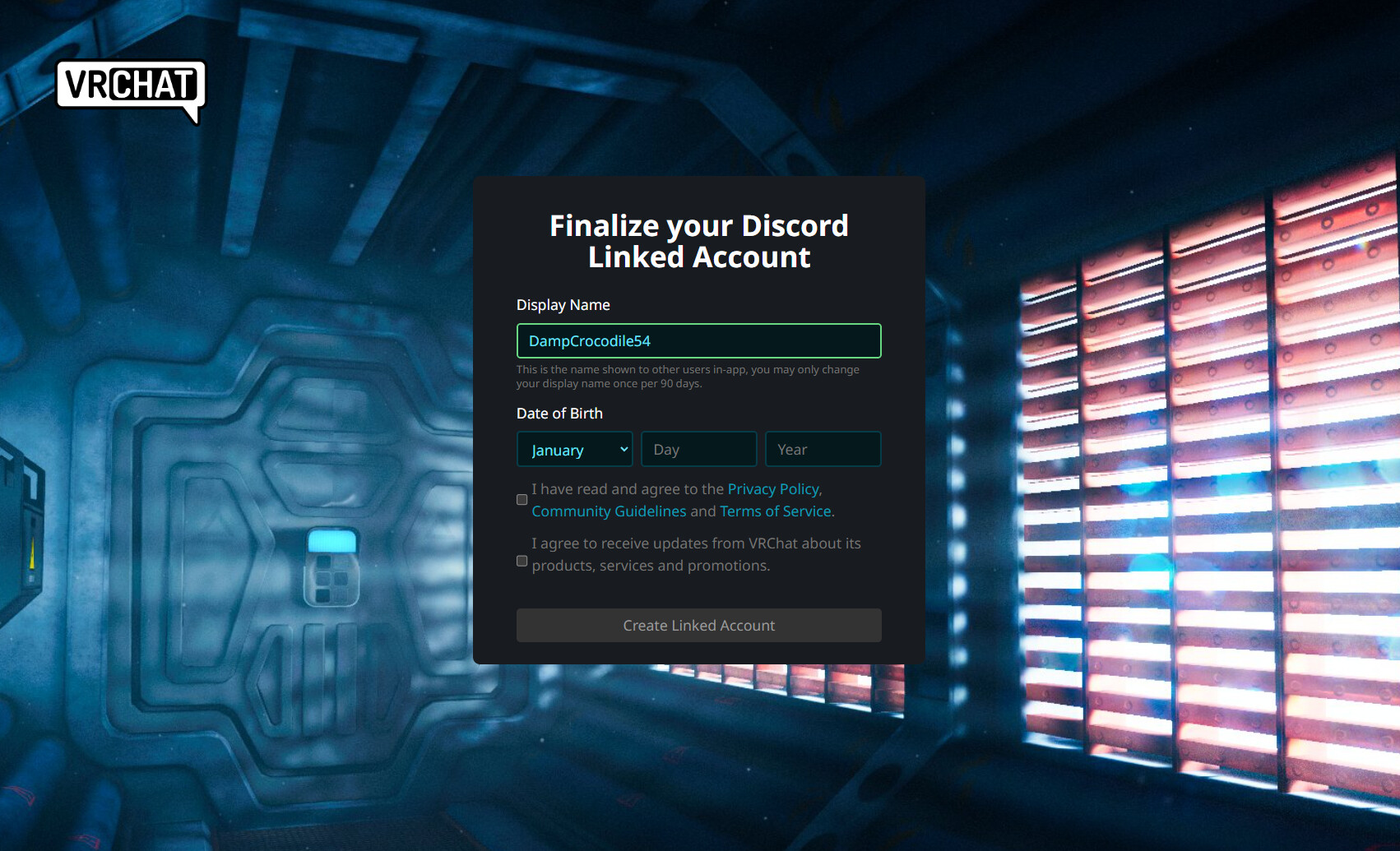
If you would like to link your Discord account to your VRChat account, but your Discord account’s email does not match your VRChat account’s email, you can head to the User Settings page of the VRChat website and link your Discord account from there. From this same page, you can also unlink your Discord account.


Logging in with Discord via the VRChat client is also currently available in Open Beta, head over there to try it out!

Steam Audio Experimentation
We’re experimenting with some changes to Steam Audio to make it behave more like human speech!
Users of Steam Audio may have noticed that other users’ voices are louder in front, quieter from behind. This is what’s called a ‘cardioid’ pattern - and Steam Audio supports using this on any sound source. Steam Audio also supports setting EQ bands on any audio source - so you can have audio sources that are more bassy or more tinny.
Unfortunately doing both at once isn’t supported on Steam Audio, presumably as it’s quite niche - but this is how human speech works! Bass frequencies are nearly omnidirectional, but high frequencies are almost entirely forward.

(Source for image!)
Fortunately as Steam Audio is open source, we’ve been able to make changes to support this change internally. Internal testing feedback currently ranges from “the actual effect of the cardioid three-band suppression seems overwhelmingly just obviously better” to “so far i cant tell any difference between the 3 band cardioid enabled or disabled”.
We’re hoping this makes crowded situations a bit more intelligible without the use of Earmuffs, as users facing away from you will be more muffled. The current experience is somewhat like if everyone in earshot was facing directly at you and talking at the same time. Give it a listen yourself though, see what you think!
Upstream Providers, and What the Recent AWS Outage Means for the Future of our Infrastructure
At VRChat, we (nowadays!) try to build infrastructure that doesn’t heavily rely on third-party SaaS or other types of service providers.
This wasn’t always the case. A couple years ago, it was common for VRChat infrastructure to be created using third-party providers because we didn’t have a dedicated DevOps team just yet.
We don’t want to throw any specific vendor under the bus, so often we call them “upstream providers” when something goes wrong.
These days, we aim for full control over the service stack we utilize over the simplicity and ease of use you get from using third-party providers. One reason for that shift is that the vast majority of outages at VRChat are caused by service failures at upstream providers.
In short, since we don’t have full control over these systems when stuff goes wrong, recovering from downtime can get complicated. We’re often at the mercy of the providers when things go wrong… and in computer science, things will go wrong.
One of these upstream providers is Amazon Web Services – or just AWS. AWS provides a set of wonderful and easy-to-use services and tools. For example, we continue to utilize the Amazon Simple Queue Service (SQS) due to its deep integration into some of our legacy service stacks.
We use SQS in combination with Valkey for cross-server communication, especially for long-running tasks that we don’t want our API endpoint servers to spend CPU cycles on. So, we kick those tasks over to dedicated worker nodes instead via AWS-powered communication channels.
When AWS suffered from a wide-spread outage earlier this week, VRChat was initially mostly unaffected.
We had one other upstream provider that we use for security related things also go offline at the same time due to this AWS outage, which prevented some users from logging in and joining instances. However, once you were already in, nothing stopped you from staying there and hanging out with your friends.
However, shortly after this, we started seeing errors relating to trying to write new messages to our SQS queues. That meant that some critical functions of our server-side application didn’t properly run their tasks anymore and instead gave up, throwing application errors back to users. This was less ideal for us because it meant user experience was below what we strive for, but it still didn’t prevent our users from interacting with unaffected API endpoints.
Fast forward to 2 hours and 30 minutes later, the upstream provider we use for security related things suddenly started to recover, users were trying to flock in again… but, our own application was still unhappy because SQS was still largely unavailable.
This meant that our own server-side application stack was now throwing a significantly higher amount of errors than normal. Eventually, these errors crossed a threshold that marked servers as “unhealthy.” Our load balancer attempted to replace these “unhealthy” application servers, but no new instances were able to get online because they never managed to satisfy the health check requirements to be considered in-service. Rinse and repeat.
Within minutes, our server-side application stack lost over half of its capacity with the remaining servers being put under more load because they were now responsible for serving more than double the amount of API requests than what they were sized for.
A few minutes later, our application stack emptied out – 0 healthy servers. We immediately began rolling out our cold start procedure in an attempt to get our application online again.
This cold start procedure consists of various steps, but the most critical ones are: blocking all user requests at the load balancer, scaling our application to twice the typical capacity, and then unblocking all requests.
We do it this way (rather than gradually ramping up traffic for a slow-start) because some of our users’ third-party applications end up flooding our application with instant retries rather than backing off properly.
By the way, if you create third-party applications that interact with our API and you’re not doing retries with proper backoffs, please fix it. Thanks!
Anyhow, our method allows us to “tank” the additional capacity up front until things stabilize, then we can scale back down after.
The problem here was that because several AWS internal control planes were acting up from this issue, we suddenly saw an extremely large portion of our compute capacity in our Auto Scaling Group disappear due to a scale-down request that reduced our capacity by 80% within seconds. Normally, this happens over a few hours.
This left us with no compute capacity to back our application instances with. Once we noticed what was happening, we tried scaling this Auto Scaling Group back up to 400% of what we needed (to give us headroom), but AWS wasn’t spinning up new compute instances for us. We were eventually left with just 3% compute capacity to serve our application traffic with.
This was obviously not enough. We proceeded to manually spin up and set up new instances, register them in the Scaling Group, allowing our application instances to finally start spinning up more capacity.
This task was very tedious due to several factors that impacted our ability to spin up compute instances, especially ones that came up healthy and not in a broken state. It took us about an hour to bring enough compute capacity online to barely serve our users with a severely degraded experience.
To get to this point, we had to take several systems offline, including the friends list and the avatars list endpoints. We also had to block certain regions from accessing our application to manage capacity. This is why while some users were able to log on, none were able to see their friends or avatars.
For the next few hours, we worked on manually bringing up more compute capacity to unblock all regions from accessing our application, eventually bring those remaining services (friends, avatars) back online as well. Eventually, everything returned to normal.
Within the last few years, we’ve migrated several services from third-party SaaS providers to in-house managed systems. We’ll continue to do so, allowing us to refine the configuration of such systems to fit our own needs. This will give us a lot more control, increasing our overall uptime, and reducing our mean time to recovery (MTTR).
As a short-term fix, we’re going to make our application more resilient to SQS interruptions, followed by a long-term solution to migrate from SQS to another in-house managed service.
Conclusion
That’s it for this Dev Update! See you November 6!